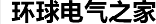發布日期:2022-10-17 點擊率:59
高性能浮點處理一直與高性能CPU相關聯。在過去幾年中,GPU也成為功能強大的浮點處理平臺,超越了圖形,稱為GP-GPU(通用圖形處理單 元)。新創新是在苛刻的應用中實現基于FPGA的浮點處理。本文的重點是FPGA及其浮點性能和設計流程,以及OpenCL的使用,這是高性能浮點計算前沿的編程語言。
各種處理平臺的GFLOP指標在不斷提高,現在,TFLOP/s這一術語已經使用的非常廣泛了。但是,在某些平臺上,峰值GFLOP/s, 即,TFLOP/s表示的器件性能信息有限。它只表示了每秒能夠完成的理論浮點加法或者乘法總數。分析表明,FPGA單精度浮點處理能夠超過1 TFLOP/s。
一種不太復雜的常用算法是FFT。使用單精度浮點實現了4096點FFT。它能夠在每個時鐘周期輸入輸出四個復數采樣。每一個FFT內核運行速度超過80 GFLOP/s,大容量FPGA的資源支持實現7個這類的內核。
但是,如圖1所示,這一FPGA的FFT算法GFLOP/s接近400 GFLOP/s。這是“按鍵式”OpenCL編譯結果,不需要FPGA專業知識。使用邏輯鎖定和DSE進行優化,7內核設計接近單內核設計的Fmax,將 其GFLOP/s提升至500,超過了10 GFLOP/s每瓦。
這一每瓦GFLOP/s要比CPU或者GPU功效高很多。對比一下GPU,GPU在這些FFT長度上效率并不高,因此,沒有進行基準測試。當FFT長度達到幾十萬個點時,GPU效率才比較高,能夠為CPU提供有效的加速功能。
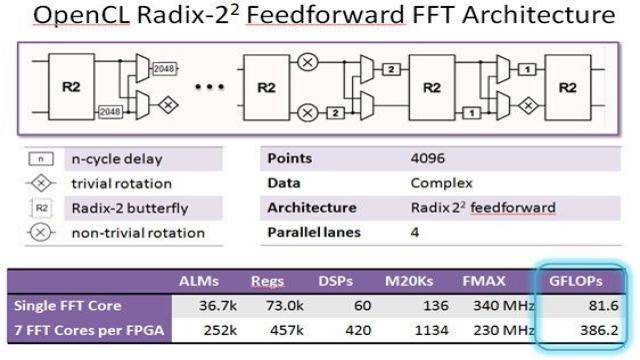
圖1:Altera Stratix V 5SGSD8 FPGA浮點FFT性能。
總之,實際的GFLOP/s一般只達到峰值或者理論GFLOP/s的一小部分。出于這一原因,更好的方法是采用算法來對比性能,這種算法能夠合理的表示典型應用的特性。算法越復雜,典型實際應用的基準測試就越具有代表性。
并不是依靠供應商的峰值GFLOP/s指標來確定處理技術,而是使用比較復雜具有代表性的第三方評估。高性能計算理想的算法是Cholesky分解。
這一算法經常用于線性代數,高效的解出多個方程,可以實現矩陣求逆功能。這一算法非常復雜,要獲得合理的結果總是要求浮點數值表示。計算需求與N3成正比,N是矩陣維度,因此,一般對處理要求很高。實際GFLOP/s取決于矩陣大小以及所要求的矩陣處理吞吐量。
表1顯示了基于Nvidia GPU指標1.35TFLOP/s的基準測試結果,使用了各種庫,以及Xilinx Virtex6 XC6VSX475T,其密度達到475K LC,這種FPGA針對DSP處理進行了優化。用于Cholesky基準測試時,這些器件在密度上與Altera FPGA相似。
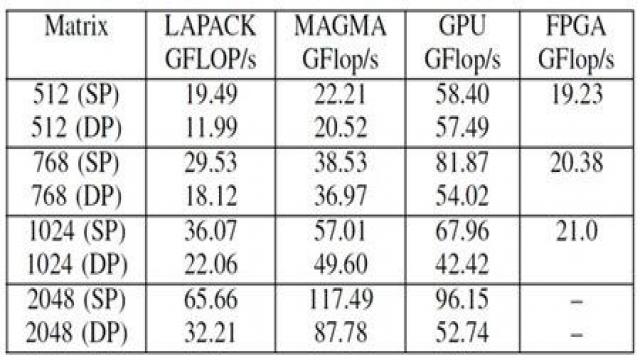
表1:田納西州大學的GPU和Xilinx FPGA Cholesky基準測試。
LAPACK和MAGMA是商用庫,而GPU GFLOP/s是指采用田納西州大學開發的OpenCL實現的。對于小規模矩陣,后者更優化一些。
中等規模的Altera Stratix V FPGA (460kLE)也進行了基準測試,使用了單精度浮點Cholesky算法。如表2所示,在Stratix V FPGA上進行Cholesky算法的性能要比Xilinx結果高很多。
表2:BDTI的Altera FPGA Cholesky和QR基準測試。
應指出,矩陣大小并不相同。田納西州大學結果是從[512×512]矩陣大小開始的。BDTI基準測試達到了[360×360]矩陣大小。原因是,矩 陣規模較小時,GPU效率非常低,因此,在這些應用中,不應該使用它們來加速CPU。在規模較小的矩陣時,FPGA的工作效率非常高。
其次,BDTI基準測試是基于每個Cholesky內核的。每個可參數賦值的Cholesky內核支持選擇矩陣大小,矢量大小和通道數量。矢量大小大 致決定了FPGA資源。較大的[360×360]矩陣使用了較長的矢量,支持這一FPGA中實現一個內核,達到91GFLOP/s。較小的[60×60] 矩陣使用的資源更少,因此,可以實現兩個內核,總共是2×39=78GFLOP/s。最小的[30×30]矩陣支持實現三個內核,總共是 3×26=78GFLOP/s。
FPGA看起來更適合解決數據規模較小的問題。原因之一是因為計算負載隨N3而增大,數據I/O隨N2增大,最終,隨著數據的增加,GPU的I/O瓶 頸不再是問題。另一項考慮是吞吐量。隨著矩陣規模的增大,由于每個矩陣的處理量增大,矩陣每秒吞吐量會大幅度下降。在某些點,吞吐量變得非常低,以至于無 法滿足很多應用的要求。在很多情況下,會分解大規模矩陣,處理每個小的子矩陣,以解決由于龐大的處理負載造成的吞吐量限制問題。
對于FFT,計算負載增加N log2 N,而數據I/O隨N增大而增大。對于規模較大的數據,GPU是高效的計算引擎。作為對比,數據長度很短時,FPGA是高效的計算引擎,更適合FFT長度達到數千的很多應用,對于GPU,FFT長度是數十萬。
GPU和FPGA設計方法
使用Nvidia的專用CUDA語言或者開放標準OpenCL語言對GPU進行編程。這些語言在能力上非常相似,而最大的不同在于CUDA只能用在Nvidia GPU上。
FPGA通常使用HDL語言Verilog或者VHDL進行編程。這些語言的最新版雖然采用了浮點數定義,不用進行綜合,但都不太適合支持浮點設計。例如,在System Verilog中,短實數變量與IEEE單精度(浮點)對應,實數變量與IEEE雙精度對應。
使用傳統的方法,將浮點數據通路綜合到FPGA的效率非常低。Xilinx FPGA在Cholesky算法上的性能很低,它使用了Xilinx浮點內核生成功能,這證實了這一點。而Altera采用了兩種不同的方法。第一種使用 基于Mathworks的設計輸入,稱之為DSP Builder高級模塊庫。這一工具包含了對定點和浮點數的支持。它支持7種不同精度的浮點,包括IEEE半精度、單精度和雙精度。它還支持矢量化,這是 高效實現線性代數所需要的。而最重要的是,它能夠將浮點電路高效的映射到目前的定點FPGA體系結構中,如基準測試所示,規模中等的28 nm FPGA,Cholesky算法接近了100GFLOP/s。作為對比,在不具有綜合能力的規模相似的Xilinx FPGA上,實現同樣的算法,使用密度相似的FPGA,性能只有20GFLOP/s。
GPU編程人員比較熟悉OpenCL。面向FPGA的OpenCL編譯意味著,面向AMD或者Nvidia GPU編寫的OpenCL代碼可以編譯到FPGA中。Altera的OpenCL編譯器支持GPU程序使用FPGA,不需要熟練的開發典型的FPGA設計。
使用支持FPGA的OpenCL,相對于GPU有幾個關鍵優勢。首先,GPU的I/O是有限制的。所有輸入和輸出數據必須由主CPU通過PCI接口進行傳輸。結果延時會讓GPU處理引擎暫停,因此,降低了性能。
FPGA以各種寬帶I/O功能而知名。這些功能支持數據通過千兆以太網和SRIO,或者直接從ADC和DAC輸入輸出FPGA。Altera定義了OpenCL標準的供應商專用擴展,以支持流操作。
即使與I/O瓶頸無關,FPGA的處理延時也要比GPU低很多。眾所周知,GPU必須有數千個線程才能高效的工作。這是由于存儲器讀取很長的延時,以 及GPU大量的處理內核之間的延時。實際上,GPU必須有很多任務才能使得處理內核不會暫停等待數據,否則會導致任務很長的延時。
而FPGA使用了“粗粒度并行”體系結構。它建立了多個經過優化的并行數據通路,每一通路一般在每個時鐘周期輸出一個結果。數據通路的例化數取決于 FPGA資源,但一般要比GPU內核數少很多。但是,每一數據通路例化的吞吐量要比GPU內核高得多。這一方法的主要優勢是低延時。降低延時在很多應用中 都是關鍵的性能優勢。
FPGA的另一優勢是很低的功耗,極大的降低了每瓦GFLOP/s。正如BDTI所測量的,Cholesky等復數浮點算法的每瓦GFLOP/s是每 瓦5~6GFLOP/s。一般很難進行GPU能效測量,但是,Cholesky的GPU性能達到50GFLOP/s,典型功耗是200W,得到的結果是 0.25每瓦GFLOP/s,單位FLOP/s的功率高20倍。
OpenCL和DSP Builder都依靠“融合數據通路”這種技術(圖2),以這種技術實現浮點處理,能夠大幅度減少桶形移位電路,從而支持使用FPGA來開發大規模高性能浮點設計。
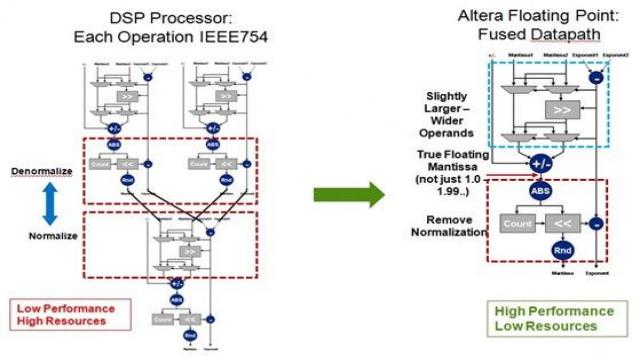
圖2:浮點的融合數據通路實現。
為降低桶形移位頻率,綜合過程盡可能使用較大的尾數寬度,從而不需要頻率歸一化和去歸一化。27×27和36×36硬核乘法器支持比單精度實現所要求 的23位更大的乘法計算,54×54和72×72結構的乘法器支持比52位更大的計算,這通常是雙精度實現所要求的。FPGA邏輯已經針對大規模定點加法 器電路進行了優化,包括了內置進位超前電路。
當需要進行歸一化和去歸一化時,另一種可以避免低性能和過度布線的方法是使用乘法器。對于一個24位單精度尾數(包括符號位),24×24乘法器通過乘以2n對輸入移位。27×27和36×36硬核乘法器支持單精度擴展尾數,可以用于構建雙精度乘法器。
在很多線性代數算法中,矢量點乘(圖3)是占用大量FLOP/s的底層運算。單精度實現長度是64的長矢量點乘需要64個浮點乘法器,以及隨后由63個浮點加法器構成的加法樹。這類實現需要很多桶形移位電路。
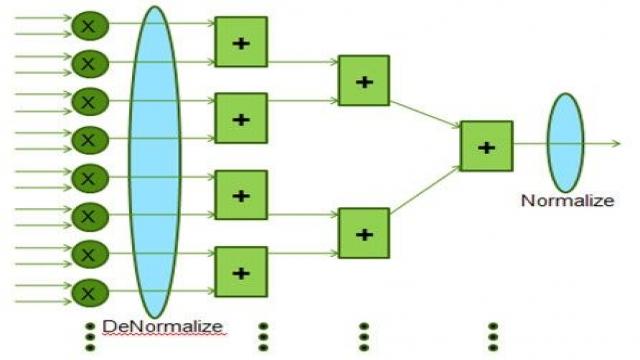
圖3:矢量點乘優化。
相反,可以對64個乘法器的輸出進行去歸一化,成為公共指數,最大是64位指數。可以使用定點加法器電路對這些64路輸出求和,在加法樹的最后進行最 終的歸一化。如圖3所示,這一本地模塊浮點處理過程省掉了每一加法器所需要的臨時歸一化和去歸一化。即使是IEEE754浮點,最大指數基本決定了最終的 指數,因此,這種改變只是在計算早期進行指數調整。
但是,進行信號處理時,在計算最后盡可能以高精度來截斷結果才能獲得最佳結果。這種方法進位額外的尾數,補償了單精度浮點處理所需要的早期去歸一化次優方法,一般從27位到36位。采用浮點乘法器進行尾數擴展,因此,在每一步不需要對乘積進行歸一化。
注意,這一方法每個時鐘周期也會產生一個結果。GPU體系結構可以并行產生所有浮點乘法,但是不能高效的并行進行加法。之所以這樣是因為不同的內核必須通過本地存儲器傳輸數據,彼此實現通信,因此,不能靈活的連接FPGA體系結構。
這一方法產生的結果要比傳統IEEE754浮點結果精確得多,如表3的測量結果所示。BDTI的基準測試獲得了相似的結果。
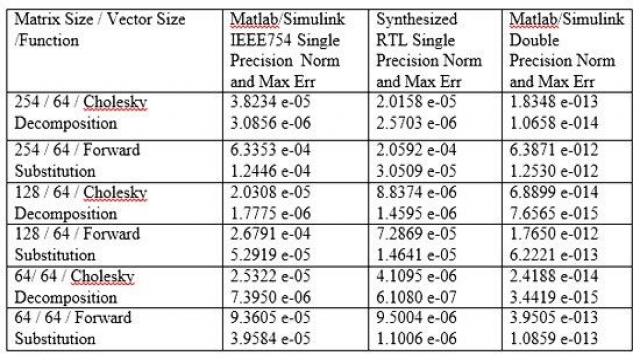
表3:FPGA相對于IEEE754浮點更精確的結果。
使用Cholesky分解算法,實現大規模矩陣求逆,獲得了表3的結果。以三種不同的方法實現了相同的算法——在Matlab/Simulink中, 使用了IEEE754單精度浮點,在RTL單精度浮點處理中,使用融合數據通路方法,在Matlab中也使用了雙精度浮點。雙精度實現要比單精度實現精度 高十億倍(109)。
表3對比了Matlab單精度;RTL單精度和Matlab雙精度存在誤差,確認了融合數據通路方法的完整性。采用了這一方法來獲得輸出矩陣中所有復數元素的歸一化誤差以及矩陣元素的最大誤差。使用Frobenius范數計算了總誤差和范數:
![]()
請注意,由于范數包括了所有元素的誤差,因此,它要比每一誤差大很多。
而且,DSP Builder高級模塊庫和OpenCL工具流程都針對下一代FPGA體系結構,支持并優化目前的設計。由于體系結構創新和工藝技術創新,性能可以達到100峰值GFLOPs/W。
總結
高性能計算應用現在有新的處理平臺選擇。對于特殊類型的浮點算法,FPGA能夠提供低延時和較高的GFLOP/s。在幾乎所有應用中,FPGA都能夠實現優異的每瓦GFLOP/s。隨著下一代高性能計算優化FPGA的推出,這種優勢會更明顯。
Altera的OpenCL編譯器為GPU編程人員提供了幾乎無縫的方法來評估這一新處理體系結構的指標。Altera OpenCL符合1.2規范,提供全面的數據庫支持。它解決了傳統FPGA遇到的時序收斂、DDR存儲器管理以及PCIe主處理器接口等難題。
對于非GPU開發人員,Altera提供DSP Builder高級模塊庫工具流程,支持開發人員開發高Fmax定點或者浮點DSP設計,同時保持了基于Mathworks的仿真和開發環境的優點。要求 高效能工作流程的FPGA開發人員多年以來一直使用這一產品,與經驗豐富的FPGA開發人員相比,所實現的Fmax性能相同。
下一篇: PLC、DCS、FCS三大控
上一篇: 直流PTC熱敏電阻恒溫

型號:R412706124
價格:面議
庫存:10
訂貨號:R412706124
型號:6810.01.A
價格:面議
庫存:10
訂貨號:6810.01.A
型號:J01006A0024
價格:面議
庫存:10
訂貨號:J01006A0024
型號:6806.17.B
價格:面議
庫存:10
訂貨號:6806.17.B
型號:6620_SMA-50-2/199_NE
價格:面議
庫存:10
訂貨號:6620_SMA-50-2/199_NE
型號:R414710161
價格:面議
庫存:10
訂貨號:R414710161